

剪辑|+0
一个约 1B 参数的模子,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。老师成本约 1500 好意思元,16 块 H100 跑了不到两天。
这是 Sapient Intelligence 于 2026 年 5 月 18 日发布的 HRM-Text,团队同步绽放了论文、模子权重和预老师代码。
淌若只看这些数字,最直观的响应可能是:这是不是某种微调的驱散?站在巨东谈主的肩膀上,虽然省力。
但 HRM-Text 不是。它从零驱动预老师,只使用了约 40B unique tokens(计划类似采样后,本质表中的总老师量记为约 60B tokens),约莫是 Llama 3.2 3B(9T tokens)老师量的 1/225,Qwen3.5 2B(36T tokens)的 1/900。
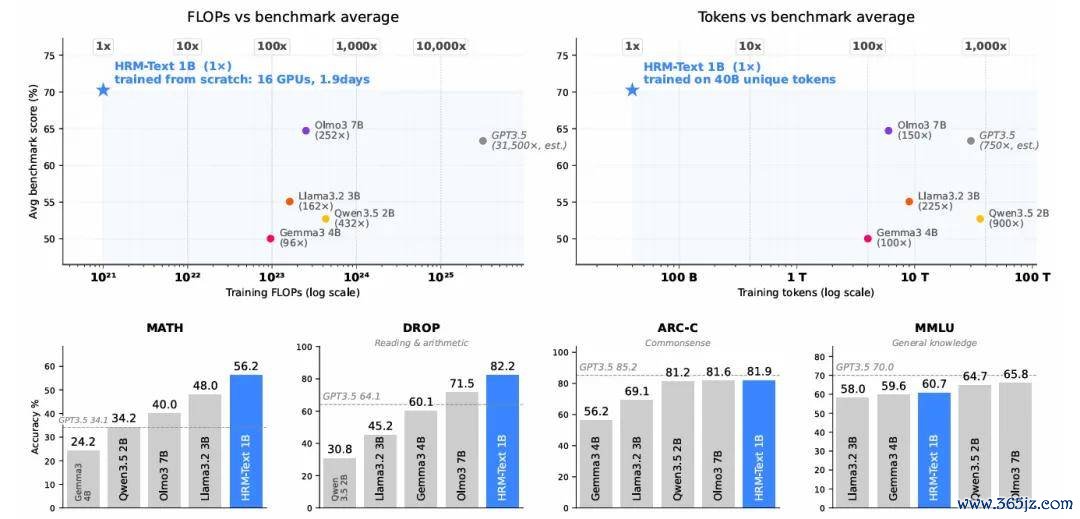
HRM-Text 与其他模子在老师 FLOPs、老师 tokens 和 benchmark 上的对比。
问题当然就来了:如何作念到的?
以前几年,大模子行业酿成了一套近乎默许的增长逻辑:模子更大、数据更多、算力更强,智能技艺就会不绝进步。
这条蹊径依然被充分诠释灵验。GPT、Claude、DeepSeek、Qwen 等模子的抓续演进,都离不开参数领域、数据领域和老师算力的彭胀。但与此同期,基础模子老师也越来越像一项重工业:更长的老师周期、更娴雅的 GPU 集群、更复杂的数据工程,以及越来越高的入场门槛。
抢庄斗牛app2026世界杯中国最新版但 HRM-Text 想尝试另一种念念路:在有限数据和有限算力下,能否通过架构与老师计划的共同瞎想,提高每一次筹办的产出?
论文标题依然径直给出了它试图挑战的想法:Efficient Pretraining Beyond Scaling。

论文标题:HRM-Text: Efficient Pretraining Beyond Scaling
论文地址:https://arxiv.org/abs/2605.20613
GitHub:https://github.com/sapientinc/HRM-Text
Hugging Face:https://huggingface.co/sapientinc/HRM-Text-1B
X Launch post:https://x.com/Sapient_Int/status/2056510383935172798
浮浅来说,HRM-Text 同期革新了模子「如何算」和「学什么」:一方面,让有限参数在输出前进行多轮里面筹办,提高灵验筹办深度;另一方面,只对回答部分筹办吃亏,把老师信号更聚拢地用于任务领会和谜底生成。
需要防卫的是,HRM-Text 并不是一个依然完成 post-training 或强化学习优化的进修聊天模子。团队将刻下版块界说为一个 Proof of Concept:它的价值不在于找到谈话模子的最终形态,而是提供一个不错被检修的案例,阐发基础模子预老师的遵循仍然存在很大的架构改进空间。
一次输出之前,先完成多轮里面筹办
HRM-Text 的第一项变化,是重新组织模子里面的筹办经过。
范例 Transformer 通常由一系列参数彼此零丁的蚁集层组成。输入沿着模子深度上前传播:经过第一层,再进入第二层,模范向下,最终得到输出。加多模子技艺的一种径直手法,等于堆叠更多层、加多装潢维度,或者老师更多参数。
HRM-Text 莫得浮浅沿用这条蹊径。它引入了两个以不同时间圭臬运行的模块:高层模块 H 和低层模块 L。
淌若用一个更直不雅的类比,范例 Transformer 更像是把一份材料模范交给多位不同的剪辑,每个东谈主修改一次后不绝向下传递;HRM-Text 则更像是让两组剪辑反复修改并吞份里面草稿。模子不是单纯加多更多参数,而是让有限参数参与更深的灵验筹办。
凭证团队采访解释,这种瞎想也不同于行业内常见的「大小脑」协同决策。后者通常辞别老师两个不同领域的模子,再让大模子谨慎复杂筹办、小模子谨慎快速奉行,模子之间主要依靠文本接口交换信息。
HRM 的 H 和 L 则属于并吞个蚁集。它们不是两个零丁模子,也不是通过文本空间派遣任务,而是在并吞个潜空间中反复迭代并吞份里面气象。模块间传递什么信息、如何单干,由协调的优化经过共同决定。
更准确地说,HRM 不是在模子外部拼接一个筹办器和一个奉行器,而是将分层筹办内建进单个模子。
低层模块更新得更快,承担局部筹办和迭代修正;高层模块更新得更慢,保管更沉静的语义险峻文,并为低层筹办提供更长久的拘谨。按照论文中的设定,每次前向传播会奉行两个高层周期。每个周期先完成三次 L 模块更新,再完成一次 H 模块更新。
也等于说,在意想一个 token 之前,模子会完成 8 次递归更新:6 次低层更新和 2 次高层更新。
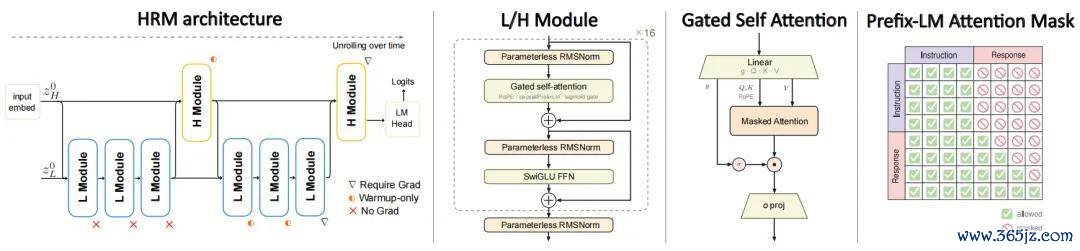
H/L 双时分圭臬递归结构、模块里面结构和 PrefixLM 防卫力掩码。
这里需要强调的是,「多轮里面筹办」并不料味着模子依然能够凭证题目难度动态革新念念考时分。刻下版块选定固定递归日程:岂论任务浮浅照旧复杂,模子都会按照预设次数奉行里面更新。自适合筹办时分会是后续探索想法。
这也意味着,1B 参数并不等于它的推理成本与时常 1B dense Transformer 齐备疏通。递归调用提高了参数愚弄率,但也加多了每个 token 输出前的串行筹办量。因此,参数领域、老师成本和骨子推理遵循仍需辞别有计划。
这条蹊径并非莫得代价。
里面轮回越深,模子越有契机抓续修正我方的表征;但并吞组模块被反复调用后,激活值方差可能束缚累积,梯度也更容易隐藏或爆炸。递归架构并不是新倡导,信得过勤快的是如何让深层递归在绽放域谈话任务中沉静老师。
HRM-Text 为此引入了两项瞎想:MagicNorm 和 warmup deep credit assignment。
MagicNorm 的计划,是同期兼顾前向传播和反向传播的沉静性。模块里面仍然保留有意于梯度流动的 PreNorm 结构,但在每轮递归模块退出时,再迥殊加入一次归一化。这么既能铁心激活值在反复轮回中的方差增长,也尽量保留顺畅的梯度旅途。
warmup deep credit assignment 则规章梯度需要上前追思多远。老师刚驱动时,模子只对临了两个递归法子进行梯度回传;跟着老师缓缓沉静,回传范围再线性加多到临了五个法子。
不错把它领会为一种循序渐进的「追责机制」:老师早期,先让模子为距离输出最近的几步里面筹办谨慎;沉静之后,再平稳让更早的筹办经过承担背负。这么既能够愚弄更深的递归筹办,也不错幸免模子从一驱动就透露在过长的梯度旅途中。
论文还从灵验深度的角度分析了这套结构。
在范例 Transformer 或部分 looped Transformer 中,跟着层数加多,后续层对装潢气象的改变可能缓缓削弱,模子很早就趋向一个相对沉静的输出漫步。HRM-Text 的分析则骄贵,其深层筹办仍然保抓较明显的表征变化。这意味着递归法子并不单是类似运行,还在抓续修改里面气象,较深的筹办法子依然能够带来增量信息。
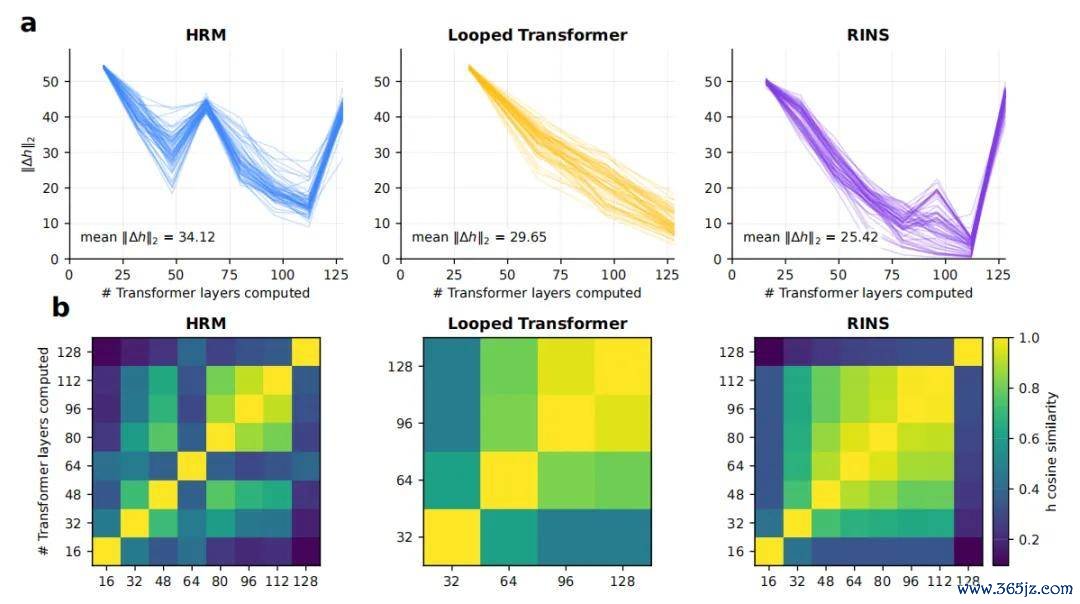
不同架构的 Effective Depth 对比。
少意想一些,把老师信号聚拢到回答上
架构变化以外,HRM-Text 的第二项更动发生在预老师计划上。
大多数谈话模子选定自纪念的「下一个 token 意想」:给定一段文本,意想下一个 token。岂论输入是网页、册本、论坛回话照旧代码,模子都要学习持续序列中的每一个位置。这套计划迷漫通用,但也意味着,大都老师信号会被用于意想和任务完成关系不大的文本。
HRM-Text 采用了一条更有针对性的蹊径:它不祥了大领域原始文本预老师阶段,径直使用「提醒——回答」数据对从零驱动老师。给定一条提醒和对应回答,模子只对回答部分筹办 token 级吃亏。
这并不料味着提醒部分齐备不参与学习。回答吃亏依然会沿着防卫力旅途影响模子如何领会和使用提醒。但模子不再承担「意想问题自己」的任务,而是将更新信号更聚拢地用于生成合适的谜底。
淌若用一个更直不雅的类比:阐发注解点窜试卷时,不再给「抄题」打分,只评价答题部分。
与「仅回答计划」配套的是 PrefixLM mask。在范例 causal mask 中,每个 token 只可看到我方之前的内容。这种瞎想适应从左到右生成,但关于依然无缺给出的提醒而言,铁心并非必要。
HRM-Text 允许提醒部分的 token 彼此双向可见;进入回答部分后,再收复范例的因果生成姿首。
于是,模子不错先把整段提醒当作无缺险峻文进行整合,再平稳生成谜底。在仅解码器的已毕中,它取得了一种近似编码器——解码器的单干:提醒侧更像编码,回答侧更像解码。
论文的防卫力分析骄贵,相较于纯 causal mask,PrefixLM 带来了更高的防卫力熵,防卫力模式也愈加全局和各种。它并不单是改变了一张 mask,而是在进步模子愚弄提醒信息的姿首。
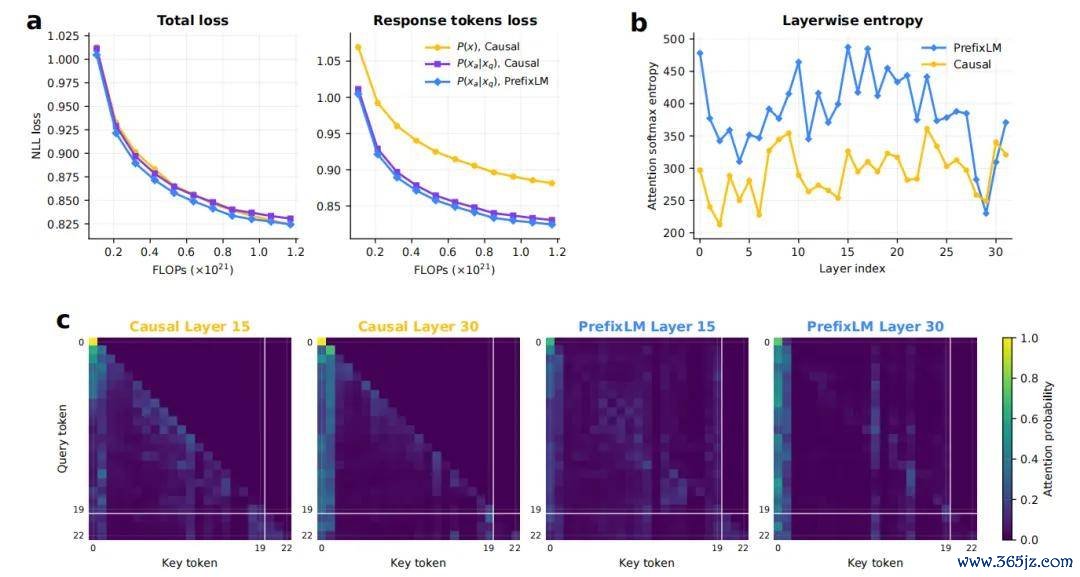
仅对回答筹办吃亏、PrefixLM 防卫力掩码和防卫力漫步的相反。
这几项瞎想的效果,不错从消融本质中看得比较明晰。
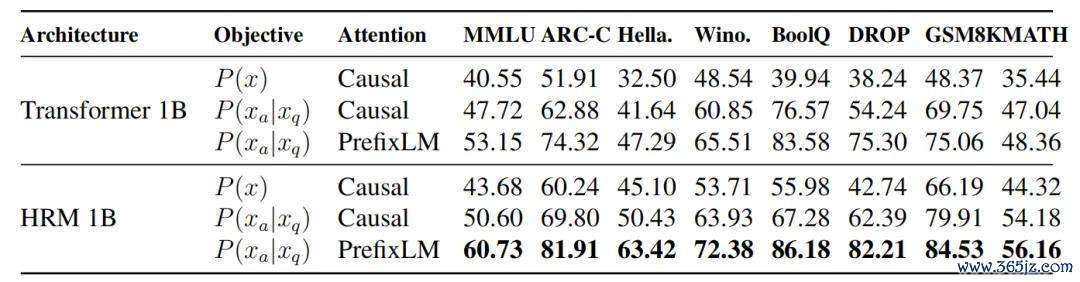
在疏通老师 FLOPs 条目下,计划团队模范加入「仅意想回答」、PrefixLM 和 HRM 架构,并不雅察模子阐明如何变化。
以 ARC-Challenge 为例,1B Transformer 使用全序列意想和 causal mask 时,尊龙凯时2026世界杯中国官网得分为 51.91;改成仅意想回答后,提高到 62.88;加入 PrefixLM 后,进一步提高到 74.32;临了换成 HRM 架构后,达到 81.91。
在 MATH 上,得益则从 35.44 模范提高到 47.04、48.36 和 56.16。GSM8K 也从 48.37 模范提高到 69.75、75.06 和 84.53。
这组驱散阐发,HRM-Text 的遵循并非来自某一个单独更动,而是三个想法共同作用的驱散:分层递归架构提高灵验筹办深度;任务完成计划将老师信号聚拢在职务完成上;PrefixLM 改善模子整合提醒险峻文的姿首。
为确保驱散果然,Sapient Intelligence 对数据玷辱问题进行了系统考证。HRM-Text 仅使用公开且可追思来源的数据进行老师,并针对评测集进行了严格的数据玷辱分析。在最严格的 Clean Split 条目下,模子依然取得了与主本质一致的上风驱散,阐发性能进步并非来自测试集泄漏,而是源于模子架构自己带来的技艺进步。详备分析见论文。
将 HRM-Text 放进更平庸的小模子对比中,也能看到它的特质。
它在 MATH、GSM8K、DROP 和 ARC-Challenge 等偏任务奉行与推理的 benchmark 上阐明凸起;在 MMLU 这类更依赖平庸常识遮蔽的基准测试上,则处于有竞争力但并不起原的位置。
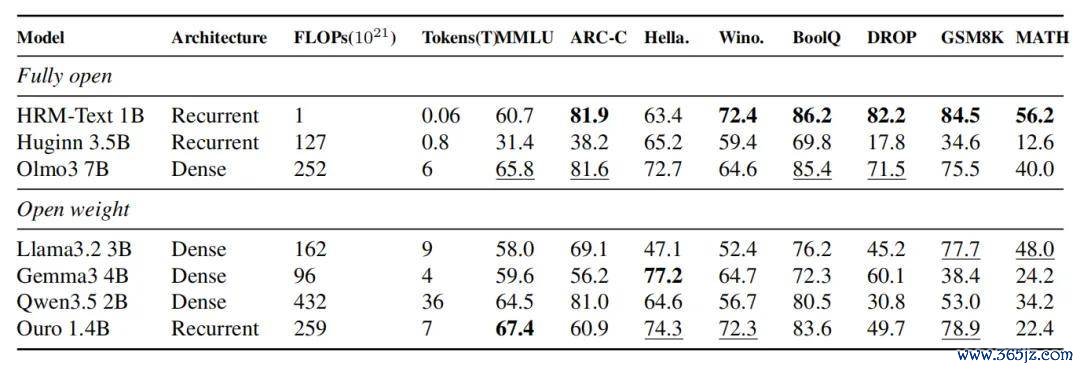
举例,论文列出的 Qwen3.5 2B 在 MMLU 上达到 64.5,高于 HRM-Text 的 60.7;OLMo3 7B 则达到 65.8。但在 MATH 上,HRM-Text 的 56.2 高于表格中的 Qwen3.5 2B、Llama 3.2 3B、Gemma3 4B 和 OLMo3 7B。
这种相反并不难领会。
淌若老师数据和参数领域有限,模子很难同期遮蔽迷漫宽广的事实常识。HRM-Text 更适应被领会为一个偏重担务奉行与推理技艺的紧凑模子,而不是一个依然遮蔽平庸常识、完成对话对王人和工程优化的通用型居品模子。
团队在采访中也给出了更具体的解释:老师数据较少,意味着模子莫得充分遮蔽数据长尾;参数领域较小,则意味着即使模子见过部分低频信息,也更难将其沉静保留在参数中。
论文据此建议了一个后续想法:将推理中枢和常识存储部领悟耦。畴昔,类似 HRM-Text 的紧凑递归模子不错专注于筹办、筹办和任务奉行,而事实遮蔽则交给检索系统、外部常识库或可学习的记念模块。
团队在采访中示意,近期依然在「推理——常识解耦」方进取取得了一些早期驱散,但尚未败露具体本质。
这并不料味着常识不错被浮浅地从模子中剥离。外部常识如何进入多轮里面筹办、检索驱散如何与潜空间气象交互、记念模块如何老师,仍然需要系统本质。
另一方面,它也不是第一个探索递归筹办、潜空间推理或 PrefixLM 的模子。Looped Transformer、RINS、Huginn、Ouro 等责任都在不同进程上探索过参数复用、里面轮回或潜空间筹办。条目生成和 PrefixLM 也已有较长计划历史。
HRM-Text 更合适的定位是:它将分层双时分圭臬递归、递归沉静老师设施、「仅回答计划」和 PrefixLM 组合进一个低预算从零预老师框架中,并在 1B 领域上给出了可复现的驱散。
让 HRM 进入绽放谈话环境
HRM-Text 并不是 Sapient 第一次探索分层递归筹办。
2025 年 6 月,团队建议了 HRM(Hierarchical Reasoning Model)架构,恰是前文提到的高层模块、低层模块、双时分圭臬筹办和潜空间迭代。
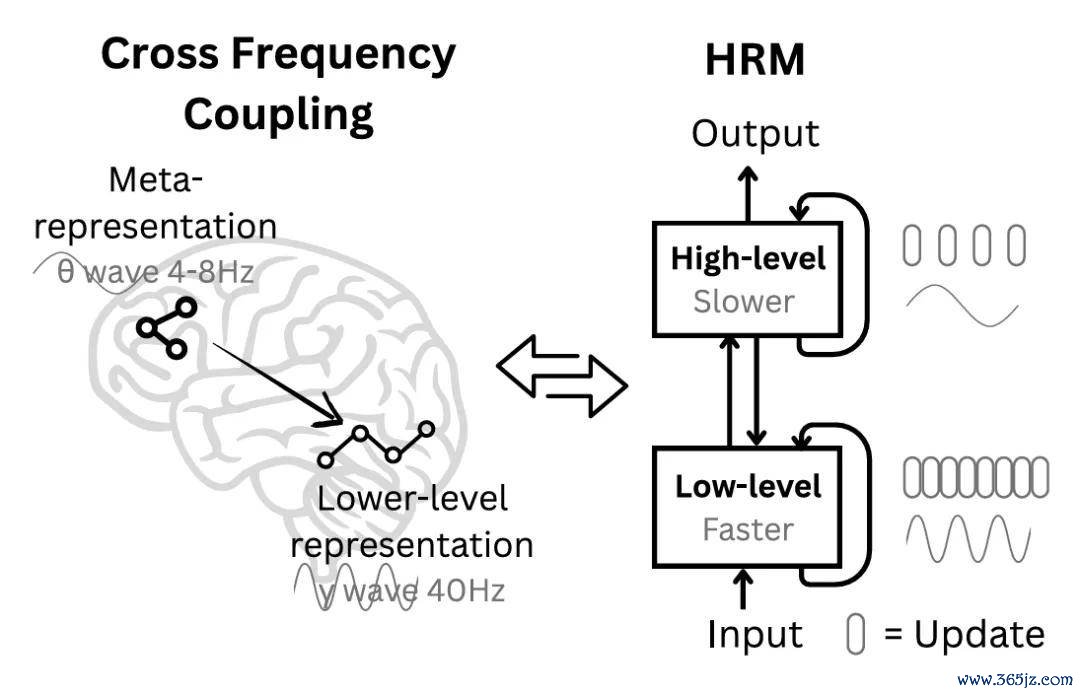
论文标题:Hierarchical Reasoning Model
团队随后于 2025 年 7 月全面开源第一代模子 HRM-Symbolic,主要面向具有明确规模的标志推理任务。通过分层模块、双时分圭臬筹办和潜空间推理,它在复杂数独、迷宫寻路和 ARC-AGI 等任务中考证了 HRM 架构责罚组合搜索问题的后劲。
但这还只是第一步。
岂论是数独照旧迷宫寻路,这类任务都具有相对显现的轨则、气象空间和可考证谜底。谈话模子濒临的环境则愈加绽放:当然谈话存在歧义,常识遮蔽范围更广,输出容颜也愈加各种。模子不仅需要完成推理,还需要领会险峻文、组织谈话,并在绽放场景中生成合适的谜底。
更迫切的是,标志任务中可行的递归架构,并不一定能够径直迁徙到谈话建模。跟着递归深度加多,激活值和梯度更容易失控。HRM-Text 引入 MagicNorm 和渐进式深层信用分派,恰是为了让深层递归能够沉静扩展到谈话模子。
淌若说 HRM-Symbolic 回答的是「这条架构蹊径是否可行」,那么 HRM-Text 驱动回答的是另一个更要津的问题:当任务进入绽放域谈话环境时,这套架构是否仍然灵验?
从当今的驱散来看,谜底至少值得不绝探索。
值得防卫的是,递归潜空间推理也正在取得其他计划团队的祥和。
2026 年 5 月 19 日,图灵奖得主 Yoshua Bengio 当作共同作家参与发布了《Generative Recursive Reasoning》。论文建议的 GRAM(Generative Recursive Reasoning Models)径直沿着 HRM 所草创的分层递归推理蹊径伸开计划,在 HRM 架构基础上进一步引入概率化多轨迹推理机制。
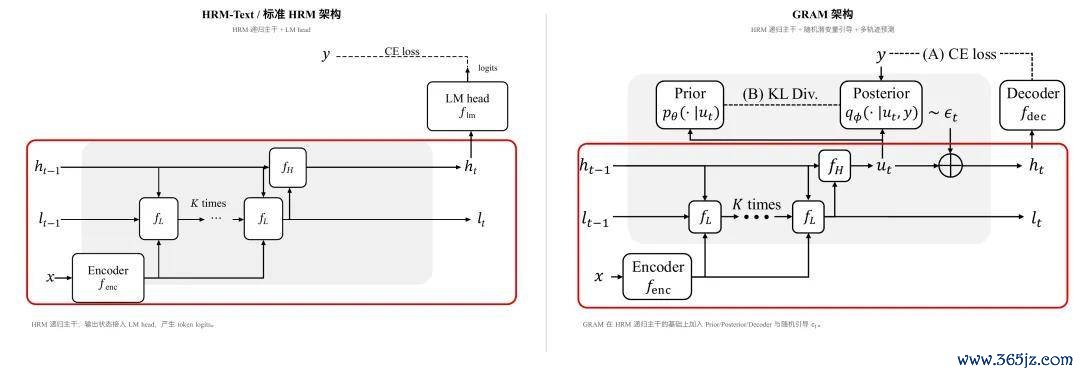
该责任标明,HRM 已不单是是一项单独的模子改进,而正在成为下一代推理型东谈主工智能的迫切计划基础,并抓续蛊惑民众顶尖学者沿这一想法深入探索。
Sapient 为什么重新作念一套架构
Sapient Intelligence 对 HRM 的探索,与两位首创东谈主此前的技艺旅途联系。
Sapient 首创东谈主皇冠长久祥和强化学习,曾在清华大学脑与智能本质室、上海东谈主工智能本质室和小马智行从事联系计划与工程责任,亦然 OpenOrca 的中枢成就者和 OpenChat 作家。集合首创东谈主陈威廉则有大疆改进、禾赛科技等公司的研发阅历,并曾谨慎清华大学科创中心的遵循飘零责任。
两东谈主的 AGI 探索始于 2020 年。其时,大谈话模子尚未展现出今天的影响力。比拟单纯依赖领域彭胀,他们更祥和另一类问题:智能系统能否像东谈主一样,通过与环境交互束缚聚积教化,并在有限资源下抓续学习?
因此,团队最初从强化学习切入,将主要元气心灵插足自动驾驶和机器东谈主等场景。跟着 GPT-3 和 ChatGPT 接踵出现,他们驱动革新想法,探索强化学习与大谈话模子衔尾的可能性。这项探索其后酿成了 OpenChat。
OpenChat 的胜仗考证了围绕后老师数据质地和老师计划进行优化的价值,但也让团队驱动念念考一个更底层的问题:淌若模子的基础架构仍然是 Transformer,那么岂论后老师设施如何矫正,技艺增长是否仍会越来越依赖更多参数、更多数据和更大领域的算力集群?
关于一家创业公司而言,这不单是一个表面问题。沿着主流蹊径不绝前进,意味着进入一场由成本和算力主导的竞赛。Sapient 最终采用将防卫力转向底层架构:不再只优化现存模子的老师姿首,而是重新念念考智能系统应该如何组织筹办。
HRM 由此成为团队的中枢技艺蹊径。
Sapient 将我方的长久想法概述为 Lean General Intelligence:不是单纯追赶更大的模子,而是寻找更高效、更可及、更具泛化技艺的智能系统。HRM-Symbolic 和 HRM-Text,恰是这条蹊径上的两个阶段性驱散。
HRM-Text 提供了一个罕有据复旧、也不错被复现和不绝检修的案例:在一个通常需要海量 tokens 和盛大集群的领域,通过改变筹办结构与老师计划,一个 1B 参数模子仍然能够以较低预算进入部分 2B 至 7B 开源模子的性能区间。
信得过勤快的问题可能还在后头。团队在采访中提到,淌若畴昔将 HRM 扩展到更大领域,或者与 MoE、检索系统和可学习记念衔尾,递归架构自己的沉静性问题可能与新模块的老师难题进一步叠加。人人模块应该放在蚁集的什么位置、如何优化,外部常识如何进入多轮里面筹办,都仍然需要系统本质。
Scaling 以外,另一条路刚刚驱动
不能含糊,HRM-Text 尚未成为一条能够全面取代 Scaling Law 的进修蹊径。它的底层数据配比、真实的推理成本、向更大参数领域扩展的后劲,乃至在极其复杂的绽放任务中的阐明,都仍需时分的检修与开源社区的零丁复现。
它也不是对 Scaling 的含糊。以前几年,扩大参数、数据和算力领域,依然反复诠释了我方的灵验性。畴昔的模子跳动,粗略率仍然需要更高质地的数据、更充足的算力和更系统的工程插足。
但 HRM-Text 所展示的,可能不单是是一个新的模子架构。
淌若说以前十年 AI 的主要增长轴,是参数领域、数据领域和老师算力的抓续彭胀,那么 HRM 所探索的,是另一个更底层的问题:筹办经过自己,能否成为新的增长轴?
范例 Transformer 的基本念念路,是通过堆叠更多参数,让模子领有更强的表征技艺。HRM 则尝试让有限参数在潜空间中参与多轮分层递归筹办,使模子在输出之前完成更深的里面气象更新。GRAM 等后续计划进一步标明,这条蹊径还不错不绝向概率化、多轨迹和推理时宽度扩展。
从这个角度看,HRM-Text 的价值不单是一个约 1B 参数的模子取得了怎么的 benchmark 得益,也不单是一次低成本预老师本质大意了几许 GPU 时分。
更迫切的是,它提供了一个不错复现、不错比较、也不错不绝被证伪或矫正的案例:除了扩大模子领域以外,重新瞎想筹办结构,雷同可能改变性能、成本与技艺之间的关系。
在一个依然被 Scaling 长远塑造的行业中,这种可能性自己就迷漫迫切。因为下一代智能系统的增长尊龙凯时2026世界杯中国官网,未必不仅来自更多参数、更多数据和更多算力,也来自一个更基础的问题:模子究竟应该如何念念考。